
مهندس ارشد توسعه نرم افزار مجموعه صباایده، فیلیمو، آپارات | Staff Engineer @Sabaidea,
الگوهای معماری میکروسرویس بخش اول: بانک اطلاعاتی

استفاده از میکروسرویسها بسته به شرایط میتواند تاثیرات مثبتی بر کسبوکار شما داشتهباشد، اما دانستن نحوه برخورد با این معماری و الگوهای مورد استفاده در آن از اهمیت بالایی برخوردار است. قبل از هر چیزی مروری از مقاله قبلی را در چند سطر بخوانید.
اهداف و اصول معماری میکروسرویسها:
- کاهش هزینهها: هزینههای کلی طراحی، پیادهسازی و نگهداری سرویسهای فناور محور کاهش میابد.
- افزایش سرعت انتشار: سرعت انتشار امکانات جدید از ایده تا انتشار افزایش میابد.
- بالابردن سطح اطمینان: این معماری باعث بهینهکردن قابلیت اطمینان در شبکه سرویسهای شما میشود.
- دسترسپذیری بهتر: دسترسی به سرویسهای شما سادهتر میشود.
اصول بنیادین معماری میکروسرویسها:
- توسعهپذیری(Scalability)
- دسترسیپذیری(Availability)
- انعطافپذیری(Resiliency)
- استقلال
- مدیریت غیر متمرکز
- ایزوله سازی در مقابل خطا
- پراویژنینگ(Provisioning) خودکار
- انتشار پیوسته از طریق سازوکار DevOps
الگوهای طراحی در حوزه میکروسرویسها:
معماری میکروسرویس علاوه بر مزایای گفتهشده و راهکارهایی که برای شما فراهم میکند، چالشها و مشکلاتی را نیز با خود به همراه دارد، اما باید بدانید که این چالشهای فنی مانند بسیاری از مشکلات در این حوزه، با انتخاب الگوهای طراحی صحیح و متناسب با صورت مسئله، قابل رفعشدن هستند.
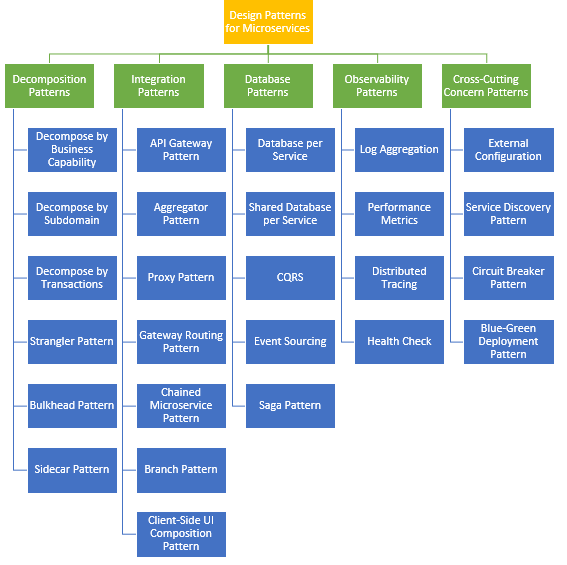
این الگوها به 5 دسته اصلی تقسیم میشوند:
- الگوهای بانک اطلاعاتی
- الگوهای جداسازی(Decomposition)
- الگوهای یکپارچگی(Integration)
- الگوهای مشاهدهپذیری(Observability)
- الگوهای مشکلات چندجانبه(Cross Cutting Concerns ) آخه من اینو چی بگم به فارسی؟! :دی
با توجه به مقدمهای که برایتان شرح دادم، قصد دارم در یک مجموعه مقالات سریالی، هر بار به سراغ یکی از این 5 دسته الگوهای طراحی بروم و مزایا و معایب هر کدام را بررسی کنم، این مقاله نیز به عنوان اولین قسمت از این سری مقالات به حساب میآید که تصمیم گرفتم در ابتدا از حوزه بانک اطلاعاتی شروع کنم زیرا که در مورد این حوزه بحثها و گفتگوهای زیادی وجود دارد.
الگوهای بانک اطلاعاتی
الگوهای مورد استفاده در بانکهای اطلاعاتی در میکروسرویسها یکی از موضوعات پر بحث و جدل درباره نحوه جداسازی میکروسرویسها است. باید گفت، الگوهای زیر جز موارد پراستفاده هستند:
- بانک اطلاعاتی جدا به ازای هر سرویس
- بانک اطلاعاتی مشترک
- الگوی Saga
- الگوی API Composition
- الگوی Event Sourcing
- الگوی CQRS
زمانی که درباره معماری بانک اطلاعاتی در میکروسرویسها صحبت میشود، باید موارد زیر را گوشه ذهن خود داشتهباشیم:
- سرویسها باید تا جای ممکن به همدیگر وابستگی نداشتهباشند تا بتوانند به صورت جداگانه توسعه پیدا کنند، بارگذاری شوند و تغییر اندازه دهند.
- برخی از تراکنشهای مرتبط به کسبوکار ممکن است نیاز به دریافت اطلاعات از سرویسهای متعدد داشتهباشند.
- بانکهای اطلاعاتی در برخی از موارد باید در چند نقطه تکراری، نگهداری و یا به اشتراک گذاشتهشوند.
- سرویسهای مختلف، نیازهای مختلفی در حوزه بانکهای اطلاعاتی دارند.
بانک اطلاعاتی جدا به ازای هر سرویس
در این الگو، میکروسرویس اطلاعات مربوط به خود را مدیریت میکند. با استفاده از این الگو اطمینان حاصل خواهیدکرد که، میکروسرویسهای دیگر اجازه دسترسی مستقیم به بانک اطلاعات سرویس دیگری را ندارند. ارتباط و یا انتقال اطلاعات از طریق APIهای تعیینشده از سمت هر سرویس قابل دسترسی است. پیاده سازی این الگو از چیزی که به نظر میاد پیچیدهتر است، زیرا نرمافزارها معمولا خیلی خوب مرزبندی نشدهاند و برای پیادهسازی لاجیک خود، به اطلاعات میکروسرویسهای دیگر نیازمند هستند، در نتیجه منجر به ارتباطات پیچیده بین میکروسرویسهای مختلف میشود.
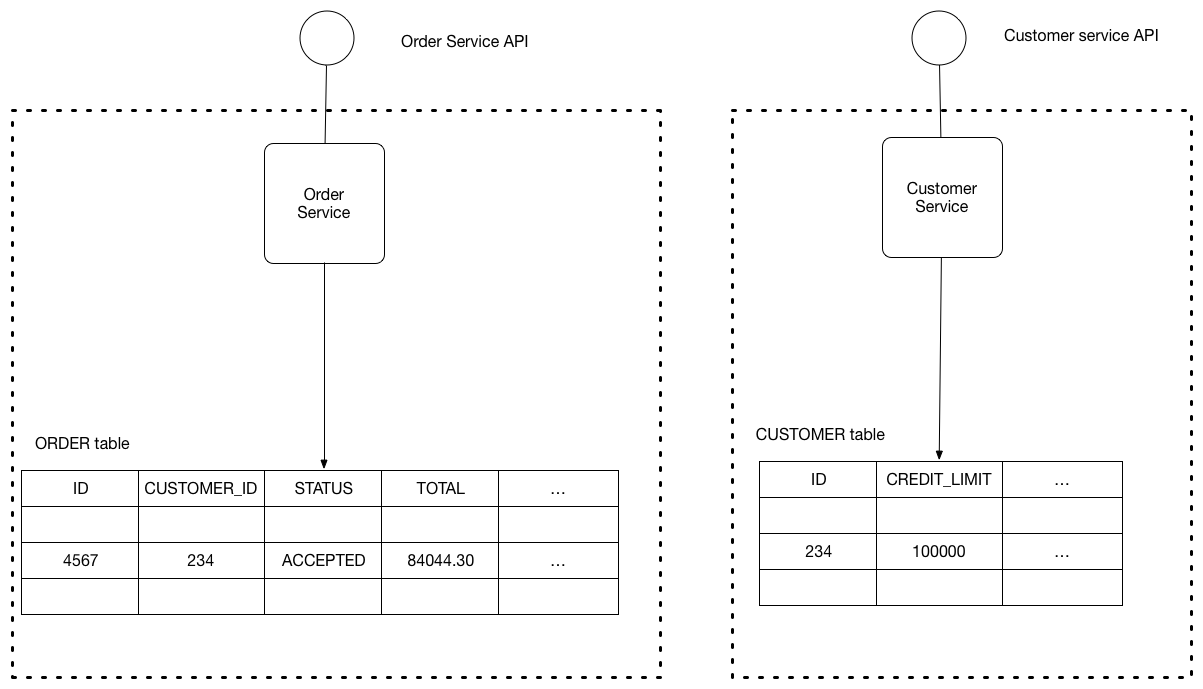
اگر موفق شوید این الگو را به خوبی پیادهسازی کنید، میتوانید از بزرگترین مزیت آن که همان وابستگی بسیار کم بین میکروسرویسها است، استفاده کنید و نرم افزار خود را از گیرافتادن در impact analysis خلاص کنید. موفق بودن این الگو به شدت به تعریف موثر حوزه بانک داده در نرمافزار شما وابستهاست. این کار برای یک نرمافزار یا یک سیستم جدید و در حال طراحی، کار سادهتری است ولی برای یک معماری مونولیتیک، جداسازی پیچیدگی موجود میتواند مشکل ساز باشد!
همچنین چالشهای دیگری نیز در این معماری وجود دارد، که میتوان به آن اشاره کرد:
پیادهسازی Business Transaction هایی که چندین میکروسرویس را درگیر میکنند و یا پیادهسازی query هایی که اطلاعات را از دو یا سه میکروسرویس مختلف دریافت میکنند.
نکته مفید دیگری در این حالت وجود دارد:
نکته مفید امکان اسکیلکردن ساده نرمافزار و استفاده از بانکهای مختص به هریک از میکروسرویسها است به طور مثال؛ در میکرسرویس جستجو میتوانید از ElasticSearch و در میکروسرویس مدیریت کاربران، از قدرت یک دیتابیس RDBM استفاده کنید.
بانک اطلاعاتی مشترک
استفاده از یک بانک اطلاعاتی اشتراکی، در زمانی که برای تیم شما چالشهای پیادهسازی بانک اطلاعاتی به ازای هر سرویس، زیادی پیچیده و مشکل ساز شود، گزینه مناسبی است. رویکرد این الگو مانند الگوی قبلی سعی در رفع مشکلات بالا دارد، با این تفاوت که از راه حل سادهگیرانهتری مانند استفاده از بانک اطلاعاتی مشترک استفاده میکند.
در اکثر مواقع استفاده از این الگو برای توسعهدهندهها کمخطرتر است، چون روش مورد استفاده کاملا مشابه روشهای مرسوم آنها مانند ACID Transaction برای حفظ یکپارچگی اطلاعات است.
در این روش اگرچه از بیشتر منافع ذکرشده برای میکروسرویسها بهرهمند میشوید، اما توسعهدهندهها که در تیمهای مختلف فعالیت میکنند باید تغییرات مورد نظر خود در بانک را با یکدیگر هماهنگ کنند. همچنین به دلیل استفاده چندین سرویس به صورت همزمان از یک بانک اطلاعاتی، امکان وقوع خطاهای ناسازگاریهای runtime نیز وجود دارد.
- به طور کلی روش بانک اطلاعاتی مشرک در بلند مدت بیشتر از اینکه مفید باشد برای شما دردسر ایجاد میکند.
الگوی Saga
الگوی Saga راهکاری برای پیادهسازی Business Transaction بین چندین میکروسرویس است. یک Saga به طور ساده زنجیرهای از تراکنشهای محلی است. به ازای هر کدام از این تراکنشها که در یک Saga اتفاق میافتد، سرویسی که آن تراکنش را انجام میدهد یک event منتشر میکند. تراکنش بعدی بر اساس خروجی تراکنش قبلی اتفاقمیافتد و اگر یکی از تراکنشهای موجود در این زنجیره به خطا بخورد، Saga یکسری از تراکنشهای اصلاحکننده را میدهد تا تغییراتی که به واسطه تراکنشهای قبلی ایجادشده را برگرداند.
در الگوی Saga از دو روش برای مدیریت مراحل استفاده میشود:
- روش Choreography : هر کدام از تراکنشها محلی، یک Domain Event را ایجاد میکند که باعث ایجاد تراکنشهای محلی در دیگر سرویسها میشود.
- روش Orchestration : یک ارکستراتور به شرکتکنندگان(میکروسرویسها) میگوید که چه تراکنشی را باید انجام دهند.
روش Choreography
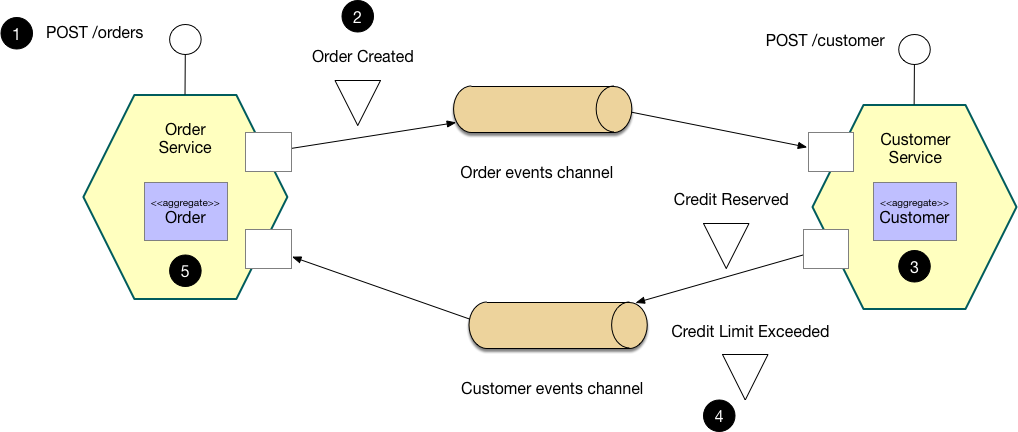
در مثال فوق مراحل زیر طی میشوند:
۱. سرویس `Order Service` درخواستی را از POST /orders دریافت و یک order را در حالت Pending ایجادمیکند.
۲. سپس یک event از نوع Order Created ایجاد میشود.
۳. در سوی دیگر سرویس Customer Service به event از نوع Order Created گوش میدهد و هنگامی که این درخواست را دریافت میکند سعی خواهد کرد به اندازه هزینه سفارش از اعتبار مشتری به صورت رزروشده نگهداریکند.
۴. در مرحله بعد نتیجه تلاش خود را به صورت یک event ارسال میکند.
۵. مدیریتکننده event سرویس Order Service در این مرحله event بالا را دریافت و بر اساس اینکه آیا مشتری اعتبار دارد یا خیر؟ سفارش را تایید و یا رد میکند.
روش Orchestration
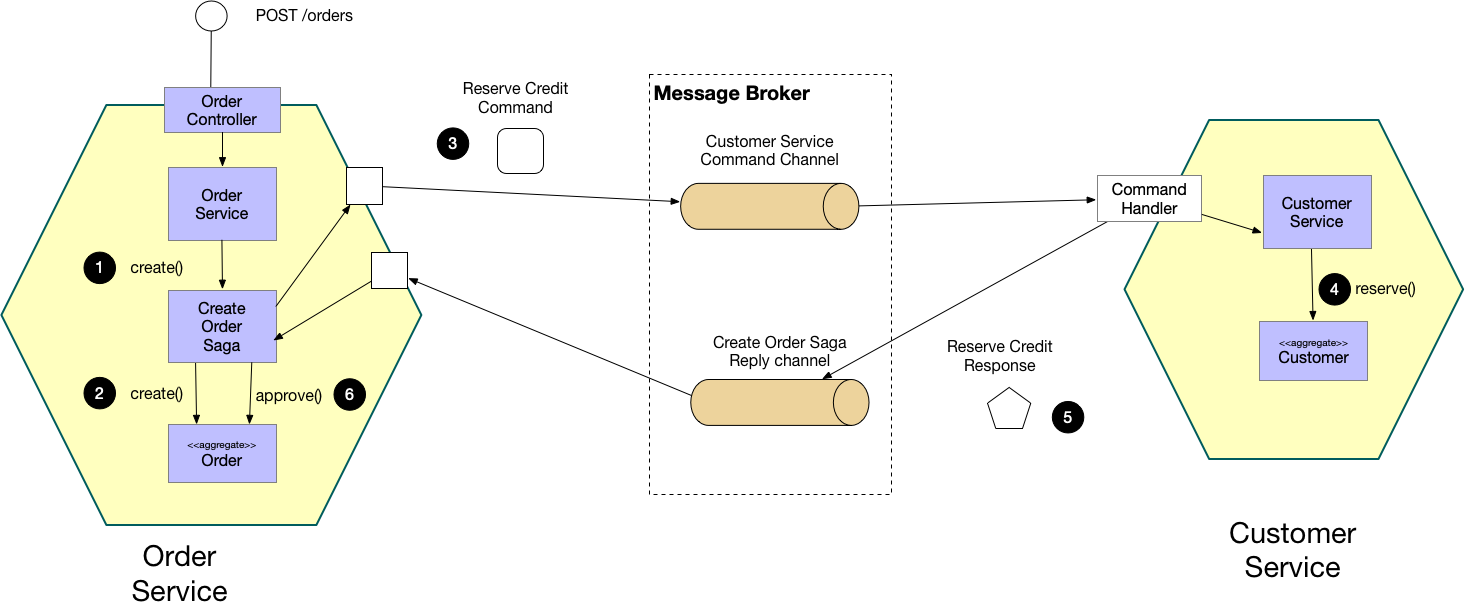
در مثال فوق مراحل زیر طی میشود:
۱. سرویس `Order Service` درخواستی را از POST /orders دریافت میکند و یک Saga Orchestrator از نوع Create Order میسازد.
۲. این ارکستریتور یک سفارش در حالت pending ایجاد میکند.
۳. سپس یک دستور Reserve Credit را از طریق Message broker برای Customer Service ارسال میکند.
۴. در این مرحله Customer Service پاسخ این درخواست را برای ارکستریتور ارسال میکند.
۵. ارکستریتور براساس اینکه پاسخ سرویس مشتریان چه بودهاست، سفارش را تایید و یا رد میکند.
همانطور که میبینید، این روش به شدت با روش سنتی ایجاد Transaction در بانک اطلاعاتی متفاوت است. این روش پیچیدگیهای زیادی را به سیستم اضافه میکند، اگر چه این الگو برای حل مشکلات خاص خیلی قدرتمند است ولی به دلیل پیچیدگیهای بسیاری که دارند فقط در موارد خاص استفاده میشوند.
الگوی API Composition
این الگو، راهکاری برای مدیریت Queryهای پیچیده در معماری میکروسرویسها است. در این الگو، یک API Composer، سرویسهای دیگر را صدا میزند و اطلاعات مورد نیاز را براساس ترتیب مورد نیاز دریافتمیکند و پس از دریافت این اطلاعات، آنها را با یکدیگر به صورت in-memory ترکیب و نتیجه را به مصرف کننده API ارایهمیکند.
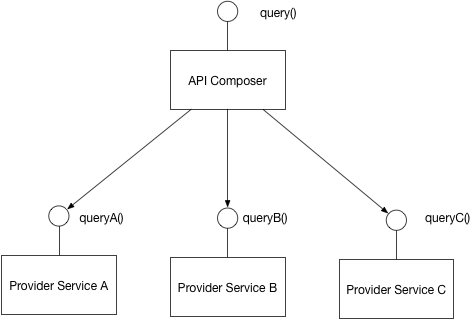
پر واضح است که مشکل این روش هزینه ترکیب اطلاعات به صورت in-memory برای Datasetهای بزرگ است.
الگوی CQRS
الگوی CQRS یا Command Query Responsibility Segregation(جداسازی مسئولیت کوئری) تلاش میکند مشکل الگوی API Composition را که بالاتر توضیح دادم، رفع کند. در این الگو، یک برنامه به Domain Eventهای ایجادشده توسط همه میکروسرویسها گوش میدهد و بر اساس آن یک View را بروزرسانی و یا اطلاعات جدید را از میکرسرویسهای مورد نظر دریافتمیکند. با استفاده از این روش شما میتوانید ترکیبهای سنگین از queryها را انجامدهید و حتی در صورت نیاز خود این سرویس query را scale-up کنید تا همیشه این اطلاعات را برای شما آماده داشتهباشد.
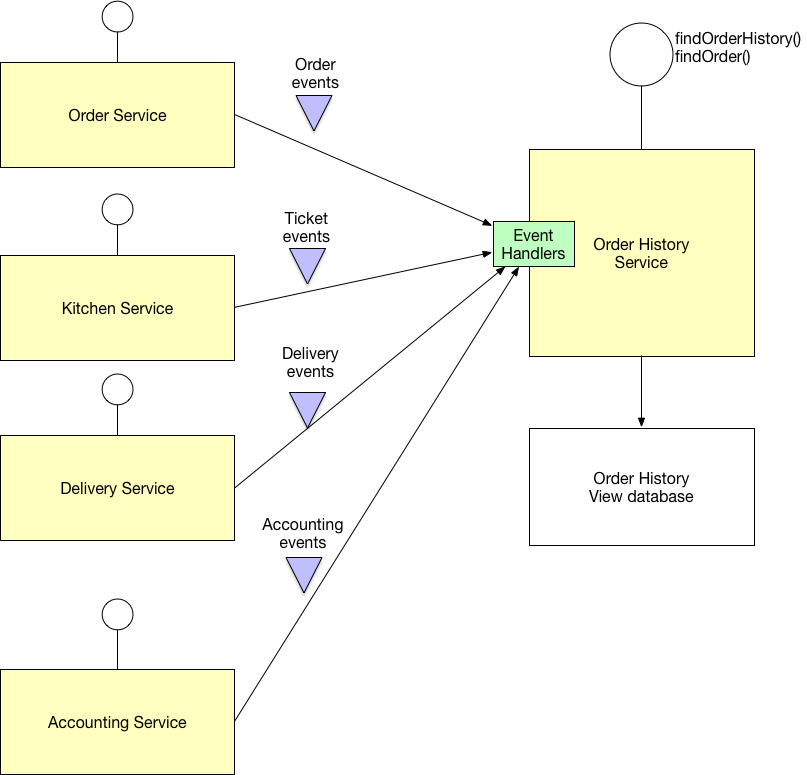
مزایای الگوی CQRS:
- امکان ایجاد چندین denormalized view را ایجاد میکند که به راحتی قابل scale کردن هستند
- باعث بهبود قاعده SoC یا Separation of concerns میشود.
مشکلات الگوی CQRS:
- پیچیدگی اجرا را بیشتر میکند.
- دیتابیس مورد استفاده برای View یا بخش Query به جای آنکه همیشه بروز و consistent باشد، بعضی وقتها consistent است.
- باعث ایجاد کدهای تکراری در سیستم میشود.
الگوی Event Sourcing
روش Event Sourcing سعی میکند مشکل بروزرسانی بانک اطلاعاتی به صورت Atomic و انتشار Event مرتبط با آن را حل کند. در این روش شما وضعیت نهایی یک رکورد را ذخیره و یا با جمع کردن مجموعه تغییراتی که از ابتدا روی این رکورد اتفاق افتادهاست، شرایط نهایی رکورد را محاسبه میکنید. هر زمانی که یک رکورد جدید ایجاد شود و یا یک رکورد موجود به روز شود یک Event ساختهمیشود. در این معماری از یک Event store برای ذخیرهسازی این eventها استفاده میشود.
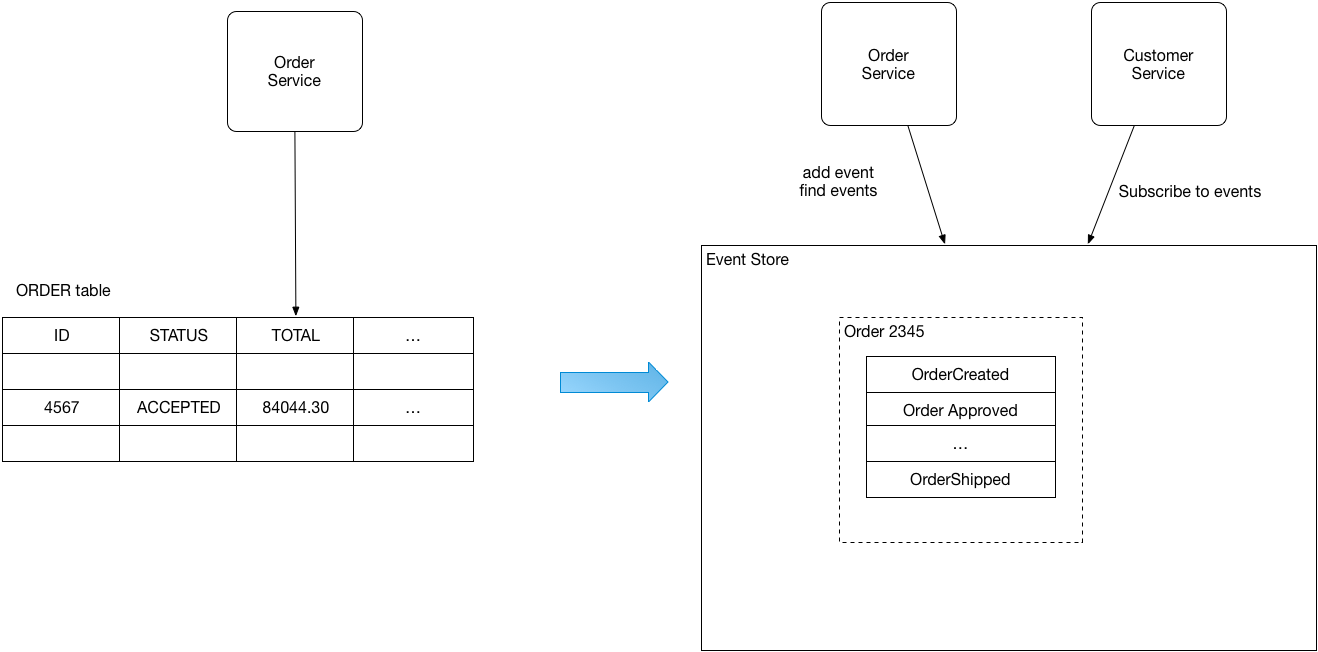
مزایای الگوی Event Sourcing:
- یکی از مشکلات اساسی معماری event-driven را برطرف میکند و به شما این امکان را میدهد که هر وقت تغییری اتفاق میافتد یک event منتشر کنید.
- از آنجا که اتفاقات را به جای آخرین وضعیت ذخیره میکند، مشکلات object‑relational impedance mismatch را کمتر میکند.
- این روش audit log صد در صد مطمئنی را برای هرکدام از entityها فراهم میکند.
- امکان ایجاد queryهای موقتی بر اساس وضعیت یک entity در هر بازه زمانی دلخواه ایجاد میکند. برای مثال وضعیت اعتبار این کاربر ۱ سال پیش چطور بودهاست؟
مشکلات الگوی Event Sourcing:
- این روش مدلی متفاوت از روش معمول برنامهنویسی در بانکهای اطلاعاتی را دارد و مدت زمان خاص خود را برای آشنایی با آن میطلبد.
- گرفتن Query از Event-Store برای تعیین وضعیت یک رکورد به صورت مکرر، کار پیچیده و غیر کارآمدی است، درنتیجه نرمافزار باید حتما از روش CQRS در کنار معماری خود استفاده کند که این به معنی کنار آمدن با دادههایی است که بعضی وقتها consistent هستند.
مطلبی دیگر از این انتشارات
نکتههای کاربردی برای تجربهنویسی در فلوی لغو اشتراک
مطلبی دیگر از این انتشارات
روزمرگیهای یک UX Writer در آپارات
مطلبی دیگر از این انتشارات
چند نکته سئویی مهم برای نوشتن توضیحات یک ویدیو