
Data Scientist & Machine Learning Engineer @SabaIdea
سیستمهای پیشنهاد دهنده فیلیمو - قسمت اول

در این دو بلاگ پست قصد داریم سیستمهای پیشنهاددهنده فیلیمو را تشریح کنیم. در قسمت اول، سیستم پیشنهاد دهنده فیلم به فیلم فیلیمو و الگوریتمها و مدلهای استفاده شده در آن را توضیح خواهیم داد و در قسمت دوم که به زودی منتشر میشود، سیستم پیشنهاددهنده شخصی سازی شده فیلیمو و روشها و نحوه ساخته شدن صفحه شخصیسازیشده را شرح خواهیم داد.
این دو بلاگ پست حاصل یک سال تلاش و تجربه تیم هوشمندسازی است، که به هدف افزایش تعامل و رضایت کاربران از فیلیمو و آپارات، تشکیل شد. این تیم در قدم اول با تمرکز بر فیلیمو، به دنبال تسهیل انتخاب کاربران از هزاران عنوان فیلم در فیلیمو بوده است. پیدا کردن فیلم مورد پسند برای کاربران ممکن است زمان زیادی از آنها بگیرد، و این هنر ماست که سلیقه کاربران را تشخیص دهیم و فیلمهایی را به آنها پیشنهاد دهیم، که انتظار میرود مورد پسندشان قرار بگیرند و در نتیجه زمان دسترسی کاربران به محتوای مورد نظرشان را کاهش دهیم.
سیستم پیشنهاد دهنده چیست؟
چطور YouTube ویدیو بعدی که ممکن است تماشا کنید را تشخیص می دهد؟ چطور Netflix فیلمهایی را فقط برای شما انتخاب میکند؟ سحر و جادو؟ خیر! در هر دو حالت، از سیستمهای پیشنهاددهنده مبتنی بر یادگیری ماشین استفاده میکنند که تشابه بین ویدیوها و فیلمها را تشخیص داده و پیشنهادهایی بر اساس سلیقه شما میدهند.
معمولا دو نوع سیستم پیشنهاددهنده وجود دارند:
- سیستم پیشنهاد دهنده صفحه اصلی
در این سیستم هر شخص، صفحه اصلی متفاوتی بر اساس سلیقه خود میبیند. برای مثال کاربران فعال در فیلیمو هر کدام صفحات اصلی متفاوتی را میبینند.
- سیستم پیشنهاد دهنده آیتمهای مرتبط
در این سیستم برای هر آیتم، آیتمهای مرتبط با آن برای کاربران نمایش داده میشود. برای مثال هر صفحه فیلم در فیلیمو فیلمهای پیشنهادی مربوط به خود را دارد.
چرا از سیستمهای پیشنهاد دهنده استفاده میشود؟
روانشناسان تحقیقات زیادی بر روی رفتار انسانها برای انتخاب و خرید اقلام مختلف انجام دادهاند. یکی از معروفترین این تحقیقات آزمایش مربا بوده است که در آن، رفتار انسان برای انتخاب مربا بین گزینههای با تعداد کم و زیاد مورد بررسی قرار گرفت. نتایج آزمایش نشان داد که درست است که گزینههای کم، جالب نیست اما گزینههای زیاد برای انتخاب هم ما را سردرگم میکند. بنابراین داشتن تعداد زیادی گزینه برای انتخاب، به نظر جذاب میآید ولی در واقع کاربران را گیج میکند و قدرت تصمیمگیری را از آنها میگیرد و در نتیجه داشتن تعداد زیادی آیتم در یک فروشگاه آنلاین یا تعداد بسیاری فیلم در فیلیمو، بدون داشتن یک سیستم پیشنهاد دهنده خوب بیشتر از این که مفید باشد میتواند مضر باشد.

به علاوه در بیشتر زمانها کاربران خودشان نمیدانند چه فیلمی ببینند و هر فیلمی که در دسترس باشد و به آنها نشان داده شود را برای تماشا انتخاب میکنند. بنابراین در صورتی که فیلمهای در دسترس، مورد علاقه کاربران باشد میزان رضایت و زمان تماشای فیلم بالاتر رفته و بیشتر از محصول استفاده میکنند. درنتیجه نیاز به یک سیستم پیشنهاددهندهای داریم که بر اساس علاقهمندی کاربران فیلمهای مناسبی را در دسترس کاربران قراردهد.
سیستم پیشنهاد دهنده فیلم به فیلم
ما در هر صفحه فیلم در فیلیمو یک ردیف از فیلمهای پیشنهادی بر اساس فیلم اصلی داریم که مورد توجه کاربران است. کاربران معمولا اگر از تماشای یک فیلم لذت ببرند علاقه مندند فیلمهای مشابه و مورد علاقه کاربران دیگر که این فیلم را تماشا کردهاند را ببینند. در هر صفحه ما فیلمهایی را پیشنهاد میدهیم که سیستم پیشنهاددهنده فیلم به فیلم بر اساس مدلهای مختلف ارائه میدهد. هدف این سیستم ارائه پیشنهاداتی هست که چهار ویژگی مرتبطبودن، جدیدبودن، متنوعبودن و غیرقابلانتظاربودن را همزمان داشته باشد و در نتیجه کاربران بیشتر از محصول استفاده کرده و رضایت بیشتری داشته باشند.
چالشها
سیستمهای پیشنهاددهنده با وجود کاربردها و مزایای زیاد، از تعداد زیادی چالش اساسی رنج میبرند که هدف الگوریتمهای ارائهشده تاکنون، رفع یک یا چند مورد از این چالشهاست؛ که در زیر به چند مورد از مهمترین آنها اشاره خواهیم کرد.
- کمبود دادگان
برای هر سیستم پیشنهاددهنده ای وجود دادگان کافی ضروری است. در ابتدای کار، مشخصات ثبت شده در پایگاه داده برای هر فیلم دارای نواقص و اشتباهاتی بود که در طول زمان، هم اطلاعات را تصحیح کردیم و هم از منابع دیگر اطلاعات تکمیلی مانند جوایز فیلمها را به آن اضافه کردیم.
- ابهام در اطلاعات
در سیستمهای پیشنهاددهنده هدف پیدا نمودن شباهت بین آیتمهای مختلف و کاربران بر اساس ویژگی های آنهاست که در برخی از کاربردها و حوزهها این کار بسیار پیچیده است. برای مثال، دادگان ما در ابتدای کار در قسمت دسته بندی در بعضی فیلمها یا نحوه دسته بندی که از ابتدا ساخته شده بود محدودیتهایی را ایجاد میکرد یا در وارد کردن اطلاعات دقت کافی وجود نداشت.
- شروع سرد (cold start)
مشکل شروع سرد تقریباً در همه سیستمهای پیشنهاددهنده وجود دارد که کارایی سیستم را به شدت کاهش میدهد. به زبانی ساده میتوان گفت مشکل شروع سرد هنگامی رخ میدهد که یک کاربر یا فیلم جدید وارد سیستم شود و سیستم در مورد آنها اطلاعات یا دانش خاصی نداشته باشد، لذا در هنگام پیشنهاد دچار مشکل میشود.
علاوه بر این چالش ها، زیرساخت های لازم برای ارزیابی آنلاین این سیستم هم با مشکلاتی رو به رو بود که در نتیجه، تعداد و کیفیت ارزیابی را تحت تاثیر قرار داد.
جمعآوری و آمادهسازی دادگان
برای جمعآوری دادگان، از دیتابیس فیلمهای فیلیمو، اطلاعات مورد نیاز فیلمها و تاریخچه مشاهده کاربران را از دادههای تعامل کاربران جمع آوری کردیم. همچنین ، برای تقویت داده های فیلمها از دو منبع معتبر یعنی IMDB و TMDB نیز استفاده شد. برای تمیز کردن دادگان، کمبودها و ایرادات زیادی را پیدا کرده و سپس آنها را کامل و تمیز کردیم. به طور مثال، ژانر قسمتهای مختلف سریال به دلیل خطای انسانی یکسان نبود، در برخی از فیلمها تعدادی از فیلدها مقدار نداشت و یا در دادههای تعامل کاربران، فیلد مشخص کننده دستگاه مورد استفاده مقدار نداشت. به علاوه یکی از نویزهایی که در فیلیمو متداول است، کاربرانی هستند که به علت استفاده چند کاربره از یک اکانت، تعداد تماشای غیر متعارف دارند که باعث خطای مدلهای ما می شوند و در نتیجه نیاز به نرمالکردن آنها بود.
روشها و مدلها
به طور کلی ساختار سیستمهای پیشنهاد دهنده شامل سه بخش است:
- تولید کاندیدا ( candidate generation)
- امتیازدهی (scoring)
- رتبه بندی دوباره (re-ranking)

تولید کاندیدا
در مرحله اول ، سیستم شروع به تولید زیر مجموعههای کوچکی از کاندیداها میکند. برای مثال، کاندیداهای تولید شده در فیلیمو از هزاران فیلم به صدها فیلم کاهش پیدا میکند. مدلها نیاز به ارزیابی کاندیداهای تولید شده دارند. هر مدل ممکن است چندین کاندیداهای مختلف تولید کند که با ارزیابی آنها بهترین کاندیداها انتخاب میشوند.
امتیازدهی
در مرحله بعد، مدل دیگری امتیازدهی و رتبه بندی کاندیداها را برای انتخاب مجموعهای از آیتمها (فیلمها) برای نمایش به کاربر بر عهده میگیرد. این مدل با ارزیابی آیتمهای مرتبط، مجموعهای کوچکتر را تشکیل میدهد که سیستم با استفاده از آن جواب دقیقتری را میتواند ارائه دهد.
رتبه بندی دوباره
در آخر، سیستم برای رتبهبندی نهایی باید محدودیتهای زیادتری را اعمال کند. برای مثال، سیستم آیتمهایی را که کاربر دوست ندارد را حذف میکند یا امتیاز محتوای جدیدتر را بالاتر میبرد. رتبهبندی دوباره همچنین میتواند کمک به تضمین تنوع، تازگی و عدالت بین آیتمها کند.
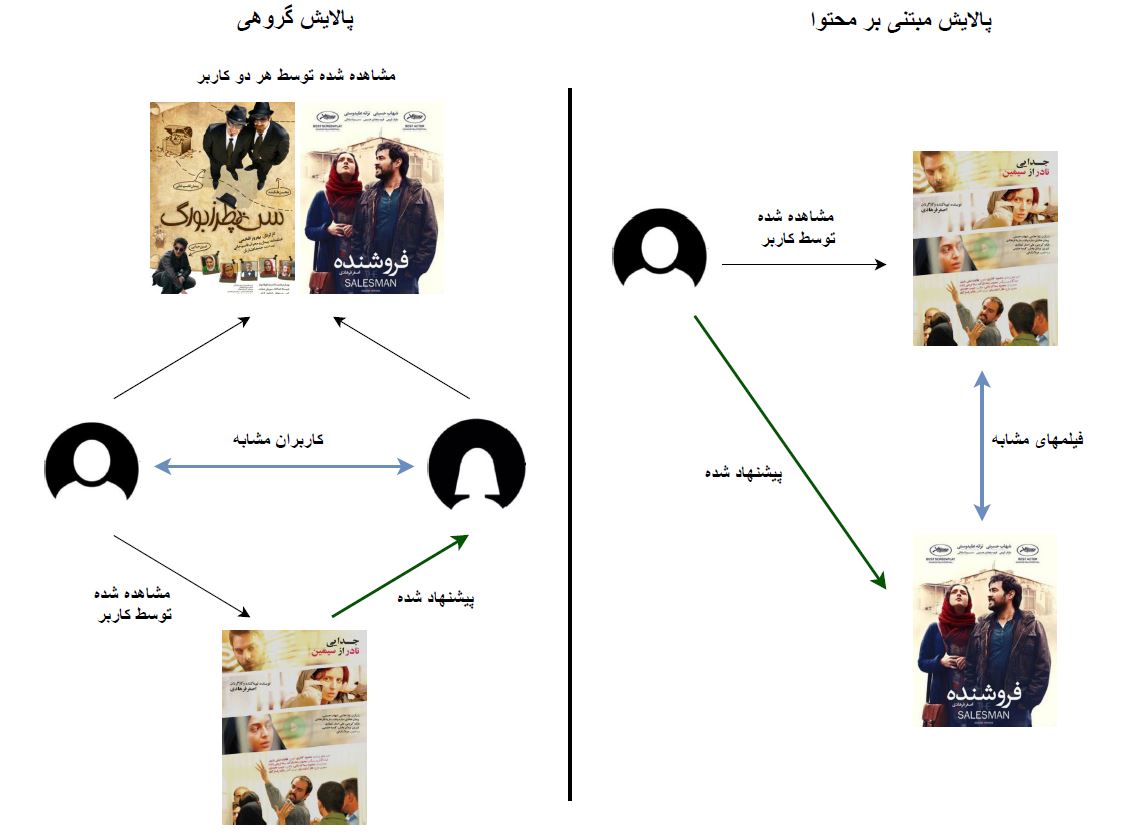
تولید کاندیداها اولین مرحله از سیستم پیشنهاددهنده است. با دادن یک کوئری، سیستم مجموعهای از کاندیداهای مرتبط را ارائه میدهد. سه روش رایج تولید کاندیدا، فیلتر کردن بر اساس محتوا (content-based filtering)، پالایش گروهی (collaborative filtering) و روشهای ترکیبی میباشند. ما در فیلیمو از روشهای مختلفی استفاده کردیم و در نهایت مدلهایی که نتایج بهتری داشتند امتیاز بالاتری گرفتند و نمایش داده شدند.
- مدلهای بر اساس محتوا
این مدلها فقط بر اساس محتوای یک فیلم، فیلمهای دیگر را پیشنهاد میدهد و در واقع هیچ تاثیری از کاربر نمیپذیرد. مهمترین مدل بر اساس محتوا استفاده شده در این سیستم مدل خوشهبندی است.
- الگوریتمهای خوشهبندی
خوشهبندی، فرآیندی است که به کمک آن میتوان مجموعهای از اشیاء را به گروههای مجزا افراز کرد. هر افراز یک خوشه نامیده میشود. اعضاء هر خوشه با توجه به ویژگیهایی که دارند به یکدیگر بسیار شبیه هستند و همچنین میزان شباهت بین خوشهها کمترین مقدار است. در چنین حالتی هدف از خوشهبندی، نسبت دادن برچسبهایی به فیلمها است که نشاندهنده عضویت هر فیلم به خوشه است.
مهمترین ویژگیهایی که برای خوشهسازی فیلمها مورد استفاده قرار گرفت به شرح زیر است: ژانر و دسته بندی، سال ساخت، نوع محتوا (سریال یا فیلم)، گروه سنی، کارگردان(ها)، ایرانی یا خارجی، بازیگران. این ویژگیها هر کدام با توجه به نتایج ارزیابیها، وزنهای متفاوتی دارند و در ضمن تعدادی از این ویژگیها در مرحله بعد از خوشهبندی، برای رتبهبندی دوباره هر فیلم نیز مورد استفاده قرار میگیرد.
الگوریتمهای زیادی را برای تست و ارزیابی خوشهبندی مورد بررسی قرار دادیم که در زیر اسامی آنها را آوردهایم. در نهایت با توجه به نتایج خوشهها از الگوریتم Hierarchical clustering که بهترین نتیجه را داشت استفاده کردیم. البته باید توجه داشت تعداد حالتها برای همه الگوریتمهای خوشهبندی و به دست آوردن بهترین پارامترهای آنها بسیار زیاد بود و ما با محدود کردن آنها به این نتیجه رسیدیم.
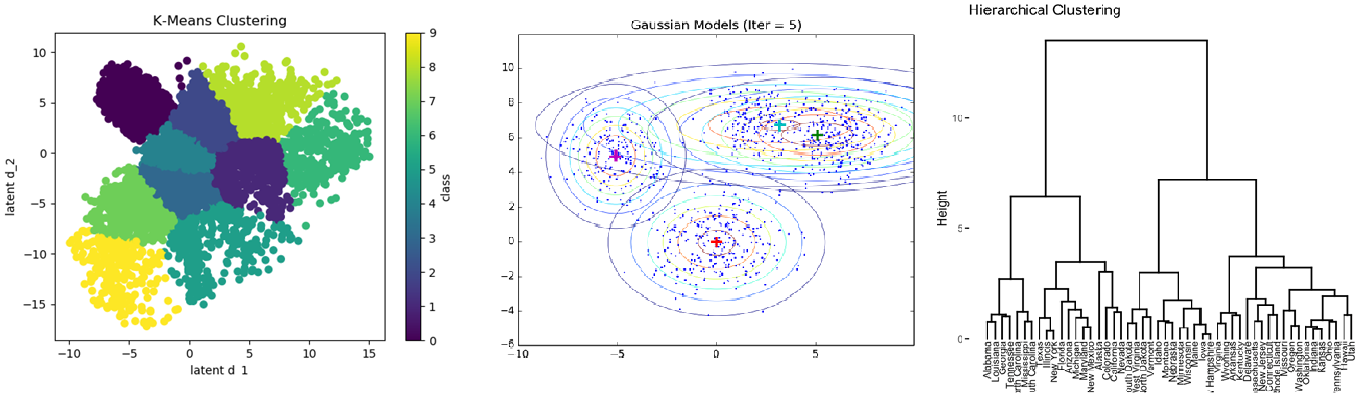
به علاوه برای نمایش خوشهها از ابزار Gephi که یکی از بهترین ابزارها در این حوزه است، استفاده کردیم.
- مدلهای پالایش گروهی
این مدلها فقط بر اساس تاریخچه تماشای کاربران ساخته و به روز رسانی میشود و محتوای فیلمها تاثیری بر روی آنها ندارد. در این سیستم ما از مدلهای word2vec و (Global Vectors(GloVe به عنوان مدلهای پالایش گروهی استفاده کردیم.
- مدلهای word2vec و GloVe
امروزه یکی از مرسومترین و رایجترین روشها در زمینه پردازش زبان طبیعی، محاسبه و نشان دادن هر کلمه توسط یک بردار است. در میان این روشها، skip-gram با نمونههای منفی ( skip-gram with negative sampling) یکی از روشهای شناخته شده است . میتوان نشان داد که سیستمهای پیشنهاد دهنده آیتم به آیتم مبتنی بر پالایش گروهی را نیز میتوان با استفاده از روشهای موجود در پردازش زبان طبیعی مانند skip-gram مدلسازی نمود. بنابراین همانند محاسبه بردار برای نمایش کلمات در فضای برداری میتوان برای هر آیتم نیز برداری منحصر به فرد را محاسبه نمود. برای این منظور تنها لازم است لیست تعامل کاربر با آیتمهای مختلف را همانند یک جمله فرض کرد. به عنوان مثال یک کاربر فیلیمو که علاقه ی زیادی به فیلمهای کمدی-ایرانی دارد احتمالا تعداد زیادی از این نوع فیلم را مشاهده نموده است. بنابراین به احتمال زیاد، در لیست فیلمهای مشاهده شده توسط این کاربر، فیلمهای کمدی-ایرانی زیادی در کنار یکدیگر قرار گرفته اند. روشهایی مانند skip-gram در پردازش زبان طبیعی نیز بر پایهی چنین فرضی عمل میکنند، یعنی کلمات نزدیک به هم موجود در یک جمله به احتمال زیاد دارای شباهت زیادی از لحاظ معنایی با یکدیگر میباشند. به همین ترتیب لیست فیلمهای دیده شده توسط هر کاربر میتواند دارای فیلمهایی باشد که شباهت زیادی از لحاظ ژانر، بازیگر، کارگردان و عوامل دیگر (به نوعی شباهت معنایی) با یکدیگر دارند. از این رو می توان لیست فیلمهای مشاهده شده توسط تمامی کاربران را همانند جملاتی در نظر گرفت و با کنار هم قراردادن این لیستها ( جملات) در کنار یکدیگر مجموعه دادهای ( متن ) را فراهم نمود. در این مجموعه داده هر فیلم همانند یک کلمه در نظر گرفته میشود که میتوان با استفاده از روشهایی مانند skip-gram و word2vec برای نمایش هر یک، برداری را محاسبه نمود. پس از محاسبه بردار متناظر با هر فیلم، برای یافتن فیلم مشابه با یک فیلم دیگر، تنها لازم است نزدیکترین همسایههای برداری آن فیلم را محاسبه نمود.
نتایج به دست آمده از این مدل بسیار قابل قبول می باشد اما مشکلاتی نیز دارد. به عنوان مثال، هنگام ترند شدن برخی فیلمها در فیلیمو، تعداد زیادی از کاربران که دارای سلایق مختلف می باشند فیلمهای مشابهی را مشاهده میکنند که همین امر باعث می شود فیلمهای مختلفی که بعضا هیچ گونه شباهتی با یکدیگر ندارند در کنار یکدیگر قرار بگیرند و باعث کاهش کیفیت مدل شوند. یکی دیگر از مشکلات این روش، شروع سرد برای آیتمهای جدید یا بسیار کم بازدید میباشد. در واقع به دلیل کمبود تعامل کاربران با این دسته از آیتمها، فراوانی آنها در دادههای آموزشی بسیار کم است و از این رو مدلسازی آنها در فضای برداری به درستی انجام نمیشود. این مشکل در پردازش زبان طبیعی نیز برای کلمات بسیار کم کاربرد وجود دارد.
مدل GloVe نیز مانند مدل word2vec سعی بر آن دارد تا بتواند برای هر کلمه (آیتم) برداری را محاسبه نماید. اما برخلاف مدل word2vec که از یک شبکه feed forward برای این منظور استفاده میکند، مدل GloVe مبتنی بر روشهای matrix factorization میباشد. برای این منظور ابتدا یک ماتریس n * n که در آن n تعداد کلمات (آیتم) میباشد و n_ij نشان دهنده ی تعداد دفعات تکرار دو کلمه i , j با یکدیگر در یک متن میباشد، ساخته میشود. سپس با استفاده از روشهای matrix factorization این ماتریس به یک ماتریس با ابعاد کوچکتر مانند n * t تبدیل میشود. t نشاندهندهی تعداد ویژگیهایی است که برای هر کلمه در نظر گرفتهایم که در طی فرایند factorization محاسبه میشوند. در مدل word2vec، تعداد دفعات تکرار دو کلمه با یکدیگر در متون مختلف، تنها به عنوان داده آموزشی بیشتر در نظر گرفته میشود اما در مدل GloVe دفعات تکرار هر دو کلمه با یکدیگر، نقش بیشتری در فرایند آموزش دارد. باید توجه داشت که یکی از معایب بزرگ این مدل استفاده بسیار زیاد از حافظه سیستم به دلیل ساختن ماتریس مورد نظر می باشد. اما از طرفی نسبت به مدل word2vec هزینه محاسباتی کمتری دارد. به همین دلیل از GloVe در فرایند پیشنهاد فیلم به فیلم فیلیمو استفاده شده است چون به روزرسانی سریع مدل پیشنهاد دهنده در بازه های زمانی کوچکتر، اهمیت بسیار بالایی دارد.
برای به دست آوردن اندازه شباهت در فضای برداری حاصل شده دو روش مرسوم شباهت سینوسی (Cosine Similarity) و ضرب نقطه ای (Dot Product) وجود دارد که ما از روش ضرب نقطه ای در اکثر مدلها استفاده کردیم.
- مدلهای ترکیبی (hybrid matrix factorization)
این مدلها هم از ویژگیهای فیلمها و هم از تعاملات کاربران استفاده میکند. هر کدام از روشهای مبتنی بر محتوا و پالایش گروهی به تنهایی مشکلاتی دارند، اما مدلهای ترکیبی سعی دارند این مشکلات را مرتفع کنند.
برای رفع مشکلات بیان شده در مدل word2vec، می توان از روشی ترکیبی، متشکل از مدلهای پالایش گروهی و مبتنی بر محتوا استفاده نمود. با ترکیب این دو روش، علاوه بر مدل سازی فیلمها و کاربران در فضای برداری، می توان اطلاعات جانبی کاربران و فیلمها را نیز مدلسازی نمود. به عنوان مثال، میتوان برای هر یک از ژانرها، بازیگران و کارگردانها نیز یک بردار منحصر به فرد محاسبه کرد. بنابراین برای هر کاربر و آیتم یک ترکیب خطی از بردارهای ویژگی آنها در نظر گرفته میشود. برای مثال، فیلم فروشنده را میتوان با ویژگیهای زیر تعریف نمود: اصغر فرهادی، شهاب حسینی، ترانه علیدوستی و سایر عوامل فیلم، سپس بردار مربوط به این فیلم را با جمع برداری هریک از این ویژگیها محاسبه نمود. با استفاده از این روش میتوان مشکلاتی مانند «شروع سرد» را تا حد بسیار زیادی حل نمود. به عنوان مثال، میتوان تنها با ترکیب برخی از ویژگیهای یک آیتم جدید، برداری جهت نمایش آن آیتم محاسبه نمود و با جستجو در فضای برداری برای سایر آیتمها آیتم مشابه با آیتم جدید را پیدا کرد. در این روش به دلیل اضافه شدن حجم زیادی از اطلاعات جانبی برای آیتمها و کاربران، استفاده از روشهایی مانند (Alternative Least Square (ALS و سایر روشهای مبتنی بر matrix factorization به دلیل نداشتن قابلیت مقیاسپذیری امکان پذیر نمیباشد. برای آموزش این مدل میتوان از روشهایی مبتنی بر یادگیری رتبهبندی مانند BPR و یا WARP استفاده نمود. مزیت اصلی این مدل استفاده از دادههای تعاملی و ویژگیهای آیتمها و کاربران به صورت همزمان میباشد.
در این سیستم برای این روش کتابخانهها و ابزارهای مختلفی را مورد ارزیابی قرار دادیم و در نهایت از LightFM که یکی از معروفترین و پرکاربردترین آنها بود و نتایج بهتری داشت، استفاده کردیم.
علاوه بر مدلهای توضیح داده شده مدلهایی بر اساس کاوش الگوهای متناوب (Frequent Pattern Discovery) را بررسی و ارزیابی کردیم اما به دلیل نتایج نامطلوب اولیه آنها را کنار گذاشتیم.
ترکیب مدلها
نیاز شدید به سیستمهای پیشنهاد دهنده، باعث شده مدلها و روشهای زیادی برای آنها ارائه شوند. تحقیق در مورد بهترین روشی که هم با دادگان ما منطبق باشد و هم دقت بالایی داشته باشد، نیازمند مطالعه و ارزیابی بسیاری بود. یکی از بهترین منابع ما برای ایده گرفتن کنفرانس RecSys بوده است. این کنفرانس مخصوص سیستمهای پیشنهاد دهنده است و سالانه مقالات بسیار خوبی در آن ارائه میشود. ما با بهره گرفتن از این کنفرانس و منابع دیگر، مدلهایی را برای سیستمهای پیشنهاد دهنده فیلیمو تست و ارزیابی کردیم .
ما برای داشتن نتایج مطلوب، نیاز به مدلهای متنوع و ترکیب آنها در شرایط مختلف داریم. انتخاب بهترین مدلها و اولویت آنها برای سیستم پیشنهاد دهنده فیلم به فیلم، در شرایط مختلف بستگی به زمان انتشار فیلم و تعامل کاربران با آن فیلم دارد. از مدلهای مبتنی بر محتوا برای فیلمهایی که اخیرا منتشر میشوند، استفاده میشود. مدلهای مبتنی بر تعامل کاربران نیز زمانی که تعامل کاربران به حد مطلوب بعد از انتشار فیلم برسد، اضافه میشود. ترکیب این مدلها بر اساس نتایج ارزیابی مدلها بدین صورت است که مدلهایی که بر اساس ارزیابی نتیجه بهتری دارند در اولویت بالاتری برای نمایش قرار میگیرند.
ارزیابی
برای ارزیابی سیستمهای پیشنهاد دهنده به طور کلی دو نوع ارزیابی آفلاین و آنلاین وجود دارد.
برای ارزیابی آفلاین از معیارهای مختلفی استفاده میشود که ما از یکی از معروفترین معیارها یعنی normalized Discounted Cumulative Gain استفاده کردهایم. nDCG معیاری است که به کمک آن میتوان میزان کیفیت یک رتبه بندی را بررسی نمود. از این معیار معمولا در بررسی میزان کیفیت نتایج الگوریتمهای جستجو استفاده میشود. در واقع این معیار میزان مرتبط بودن خروجیها را اندازه میگیرد. ما با استفاده از این معیار مدلها را به این صورت ارزیابی میکنیم که ابتدا هر مدل برای مثال 10 فیلم پیشنهادی برای یک کاربر را ارائه میدهد و ما با استفاده از تاریخچه تماشای فیلمهایی که کاربر دیده، طبق این معیار مقایسه میکنیم. در این مقایسه میزان نزدیکی فیلمهای پیشنهادی به فیلمهایی که کاربر دیده است محاسبه میشود و در نهایت هر مدلی که nDCG بالاتری داشته باشد اولویت بالاتری میگیرد.
به طور کلی یکی از چالشهای مهم ما ارزیابی این سیستم و مقایسه آن با سیستم قبلی (سیستمی که به صورت outsource مورد استفاده قرار میگرفت) بود. نسخه اول سیستم ما در مقایسه اولیه دو برابر نرخ کلیک بیشتری نسبت به سیستم قبلی داشت و در ادامه این نرخ، بهبود چشمگیری داشت. معیارها و شاخصهای دیگری هم برای ارزیابی و مخصوصا ارزیابی آنلاین وجود داشت که به علت آماده نبودن زیرساخت لازم فعلا از ارزیابی آنها صرف نظر کردیم.
معماری سیستم
شمای کلی نسخه اول سیستم پیشنهاد دهنده فیلم به فیلم فیلیمو در تصویر زیر مشاهده میکنید.
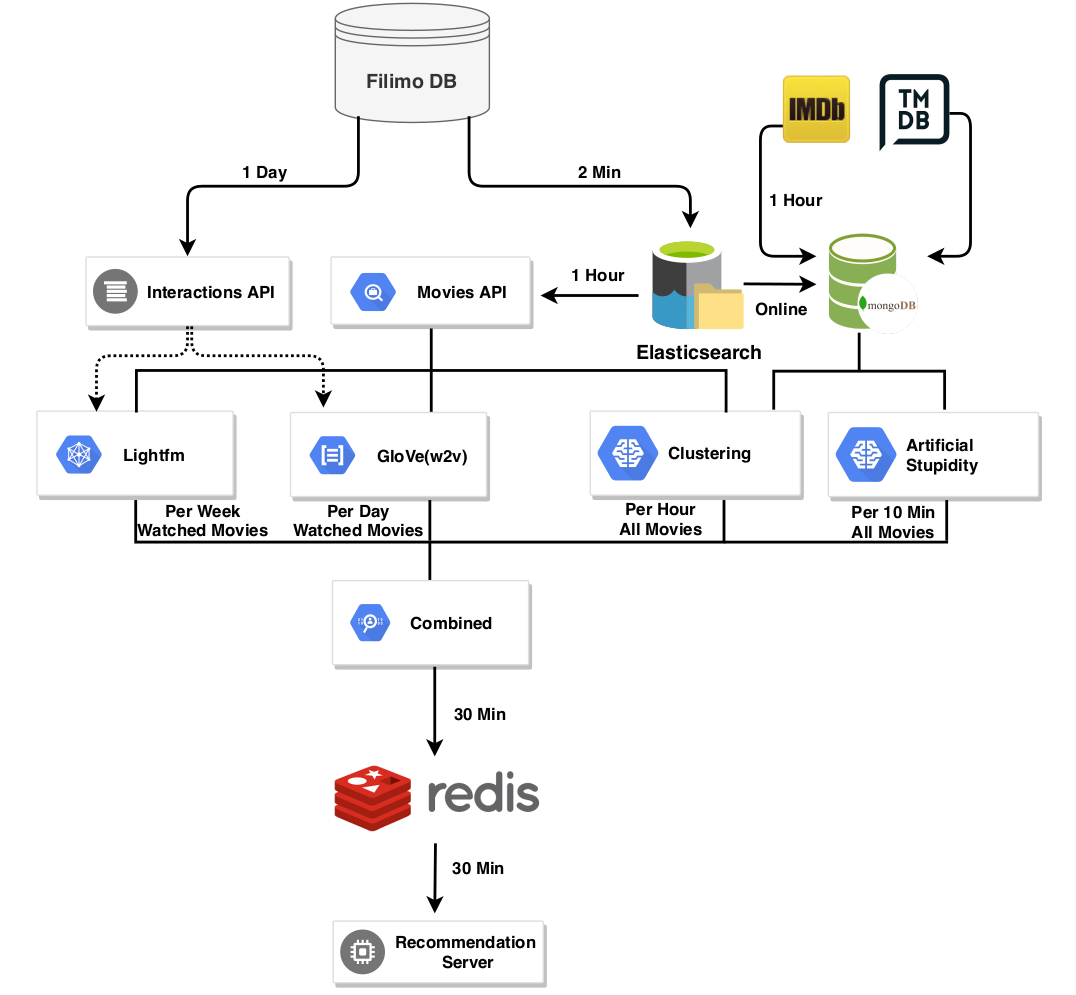
در این سیستم همانطور که مشاهده میکنید مدل ها از پایگاه دادههای مختلف، اطلاعات فیلمها و تعامل کاربران را دریافت میکنند و نتایج هر کدام از مدلها، متناسب با وزن و اولویتی که دارند ترکیب و ذخیره میشوند. تقریبا همه قسمتها به غیر از سرویسهای Artificial Stupidity و Combined به طور مختصر توضیح داده شدند.
- سرویس Artificial Stupidity
این سرویس به منظور پر کردن خلاء زمانی مدلهای هوش مصنوعی ایجاد شده و در حدود سه دقیقه میتواند به ازای هر فیلم، بهترین ۱۰۰ فیلم پیشنهادی را تولید و ذخیره کند. در حالی که مدلهای هوش مصنوعی چند ساعت تا چند روز زمان نیاز دارند تا پیشنهادات را بر اساس اطلاعات تماشای کاربران تولید کنند، این سرویس برای فیلمهای تازه منتشر شده نتایج اولیه را تولید می کند. در این سرویس، شباهت فیلمها به صورت منطقی با مقایسه میانگین وزنی اطلاعات فیلمها محاسبه میشود. دادههایی که تا این لحظه استفاده شده به ترتیب اهمیت شامل موارد زیر است:
سال ساخت، ژانر و دسته بندی فیلم، تعداد بازیگران مشترک، کارگردان، کشورهای سازنده فیلم، شباهت نوع رسانه (فیلم/سریال)، رده سنی، تعداد تگهای مشترک IMDB و TMDB، تهیه کننده و یکسانبودن کیفیت پخش
- سرویس Combined
این سرویس، در بازههای زمانی مشخص، امتیازی که هر مدل به هر پیشنهاد برای هر فیلم داده را به صورت میانگین وزنی با احتساب ضریب در نظر گرفته شده برای هر مدل محاسبه میکند و در پایگاه داده نگهداری میکند.
در پست بعدی معماری کلی سیستمهای پیشنهاددهنده ارائه خواهد شد.
در ضمن برای ساختن مدلها از زبان برنامهنویسی پایتون و برای API ها از زبان برنامهنویسی GO استفاده شده است.
ابزارهای بررسی شده
ابزارهای متعددی برای راهاندازی سیستم پیشنهاد دهنده وجود دارند که از جامعیت و انطباق پذیریهای متفاوتی برخوردارند. یکی از این ابزارها Apache Prediction IO است که در اوایل کار مورد بررسی قرار دادیم. PIO یک مجموعه ابزار متن باز یادگیری ماشین است که دارای موتورهای متفاوتی است که هر موتور، پیاده سازی یکی از الگوریتمهای یادگیری ماشین است و معماری آن به شکل زیر است:
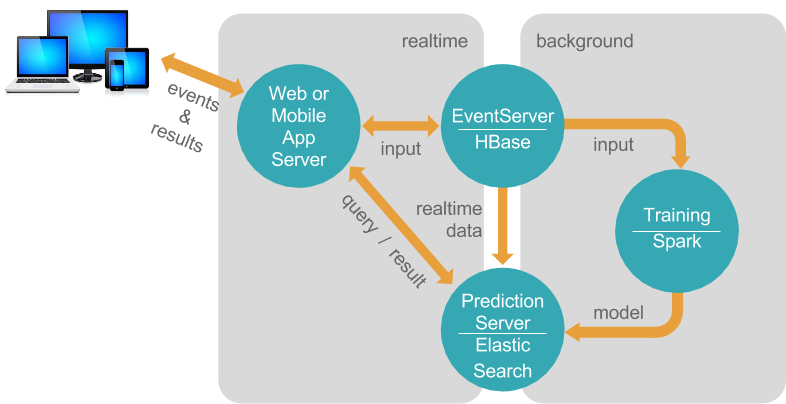
همانطور که در تصویر میتوان دید، تعامل کاربر با سیستم به صورت بلادرنگ انجام میشود؛ به این صورت که رخداد های سمت کاربر (شامل تماشا، لایک) به بخش EventServer سیستم ارسال شده و در HBase ذخیره میشوند. سپس در بازههای زمانی معین، بخش Training سیستم به صورت آفلاین، مدل ها را که بر اساس SparkML نوشته شده، روی دادههای جمع آوری شده اجرا میکند و نتیجه را در HDFS یا Elasticsearch ذخیره میکند و کاربر بدون وقفه میتواند خروجی سیستم را مشاهده کند.
از میان موتور های مختلف ما موارد زیر را امتحان کردیم:
- موتور Predictionio-template-recommender
- موتور Predictionio-template-similar-product
- موتور Template-scala-parallel-viewed then bought
- موتور Template-scala-parallel-svd-item-similarity
برای مثال ما موتور Predictionio-template-recommender را بررسی کردیم که یک موتور عمومی پیشنهاد دهنده است. با تغییر کد آن، قابلیت پیشنهاد فیلم به کاربر، فیلم بر اساس فیلم و کاربر بر اساس فیلم افزوده شد. این مدل بر اساس امتیاز هر کاربر به هر محصول، محصولات دیگری را به کاربر پیشنهاد میدهد. در morpheus امتیاز ها بر اساس رخداد های مختلفی که کاربر میتواند انجام دهد محاسبه میشود.
استفاده از از راهکارهای آماده و سریع در اولویت کار ما قرار داشت اما به دلایل زیر PIO را کنار گذاشتیم:
- نتایج اولیه نامطلوب در مقایسه با نتایج اولیه مدلهایی مانند word2vec
- لزوم تغییرات اساسی در موتورهای موجود و توسعه دشوار آنها برای کاربری خاص فیلیمو
در نتیجه به دنبال راهکارهای بنیادی برای سیستم پیشنهاد دهنده فیلیمو رفتیم و مدلهای مختلف سیستمهای پیشنهاد دهنده را بررسی، انتخاب و ترکیب کردیم.
جمعبندی
در این پست، سیستم فیلم به فیلم فیلیمو را بررسی کردیم. این سیستم به هر فیلم، فیلمهای پیشنهادی را بر اساس محتوا و تعامل کاربران نمایش میدهد. به علاوه چالشها، مدلها، نحوه ارزیابی و نحوه کارکرد سیستم را به طور مختصر بیان کردیم. این سیستم نسخه اول سیستم پیشنهاد دهنده فیلم به فیلم فیلیمو است و قصد داریم با افزودن مدلهای دیگر و بهبود مدلهای فعلی، پیشنهادات بهتری ارائه دهیم. در ادامه و در پست بعدی سیستم شخصی سازی شده فیلیمو را تشریح خواهیم کرد و نحوه ساخت صفحات شخصی سازی شده و الگوریتم خودرمزگذاری شده (Autoencoder) که الگوریتم اصلی ساخت امتیازات کاربران به همه فیلمها هست را توضیح خواهیم داد.
منابع
- https://towardsdatascience.com/recommendation-systems-in-the-real-world-51e3948772f3
- https://developers.google.com/machine-learning/recommendation/
- https://netflixtechblog.com/netflix-recommendations-beyond-the-5-stars-part-1-55838468f429
- https://netflixtechblog.com/netflix-recommendations-beyond-the-5-stars-part-2-d9b96aa399f5
- https://www.analyticsvidhya.com/blog/2019/07/how-to-build-recommendation-system-word2vec-python/
پنج نکته برای ساخت لیست پخشِ(Playlist) اثرگذار
۴۰ پیکسل کمتر چقدر تاثیر دارد؟
الگوهای معماری میکروسرویس بخش دوم : الگوهای جداسازی