
Data Scientist & Machine Learning Engineer @SabaIdea
سیستمهای پیشنهاد دهنده فیلیمو - قسمت دوم و پایانی

در مقاله قبل توضیح دادیم که برای ساختن سیستم پیشنهاد دهنده «فیلم به فیلم» چه چالشهایی وجود داشت و تیم هوشمندسازی آپارات و فیلیمو چطور نسخه اول آن سیستم را ساخت و در ادامه، در این مقاله سعی داریم چالشها و نحوه ساختن صفحه اول شخصیسازی شده فیلیمو را توضیح دهیم.
سیستم پیشنهاددهنده شخصیسازی شده چیست؟
هر صفحه در فیلیمو از مجموعهای از ردیفها ساخته شدهاست که دارای دستهبندیهای متفاوتی هستند. سیستم پیشنهاددهنده شخصیسازی شده برای هر کاربر فعال، فیلمهای صفحه اول و صفحات دیگر را مطابق با تاریخچه تماشای فیلم میسازد و برای کاربران غیر فعال و تازه واردها صفحاتی را بر اساس محبوبیت کلی و مدلها و فرمولهای دیگری میسازد.
چالشهایی که در این مسیر داشتیم
علاوه بر چالشهای مطرح شده در مقاله قبل، برای ساختن صفحه اول شخصیسازی شده، چالشهای دیگری نیز وجود داشت که در ادامه به برخی از آنها اشاره میکنیم.
- پیچیدگی ساخت ماتریس امتیازدهی کاربران به فیلمها: ساخت ماتریس امتیازدهی به همه کاربران فعال، نیاز به منابع کافی برای ساخت، ذخیره و بهروزرسانی داشت. به علاوه پیادهسازی الگوریتم مناسب برای ساخت این ماتریس، بسیار دشوار و پیچیده بود.
- پیچیدگی ساخت ردیفها و صفحات شخصیسازی شده: برای این کار به الگوریتمهایی برای چیدمان افقی در هر ردیف و چیدمان عمودی برای کل ردیفها برای ساخت صفحه نیاز داشتیم.
- استفاده چند کاربر از یک حساب کاربری: استفاده چندین کاربر یا اعضای خانواده از یک حساب کاربری در فیلیمو باعث کاهش دقت سیستم پیشنهاددهنده میشد و تا زمانی که کاربرانی با سلیقههای متفاوت از یک حساب کاربری استفاده میکنند، سیستم سلیقه غالب را اعمال کرده، در نتیجه دیگر کاربران پیشنهاد مطلوبی نمیگیرند.
- کمبود دادِگان: هر نوع تعامل کاربران با محصول از اهمیت خاصی برخوردار است و میتواند کیفیت سیستم پیشنهاددهنده را ارتقا دهد. ما دادههایی مانند کلیک کاربران را نداشتیم زیرا به یک زیرساخت قوی نیاز داشت، بنابراین فقط با تاریخچه تماشای کاربران مدلها را آموزش دادیم.
مدلهای پیشنهاددهنده شخصی
هدف از این سیستم طراحی مدلی بود که به کمک آن بتوانیم با توجه به تاریخچه فیلمهای مشاهدهشده توسط هر کاربر، فیلمهای مناسب با سلیقه آن کاربر را به او پیشنهاد دهیم. برای انجام این کار نیاز به ساخت ماتریسی داشتیم که همه کاربران به همه فیلمها امتیاز دهند. این کار به دو روش انجام شد، روش اول را که روش ترکیبی مبتنی بر فاکتورسازی ماتریس (hybrid matrix factorization) است، به طور مختصر در بخش قبل شرح دادیم و در این مقاله در ارتباط با روش دوم که استفاده از روشهای مبتنی برای شبکههای خود رمزگذار (Autoencoder) است، توضیح میدهیم.
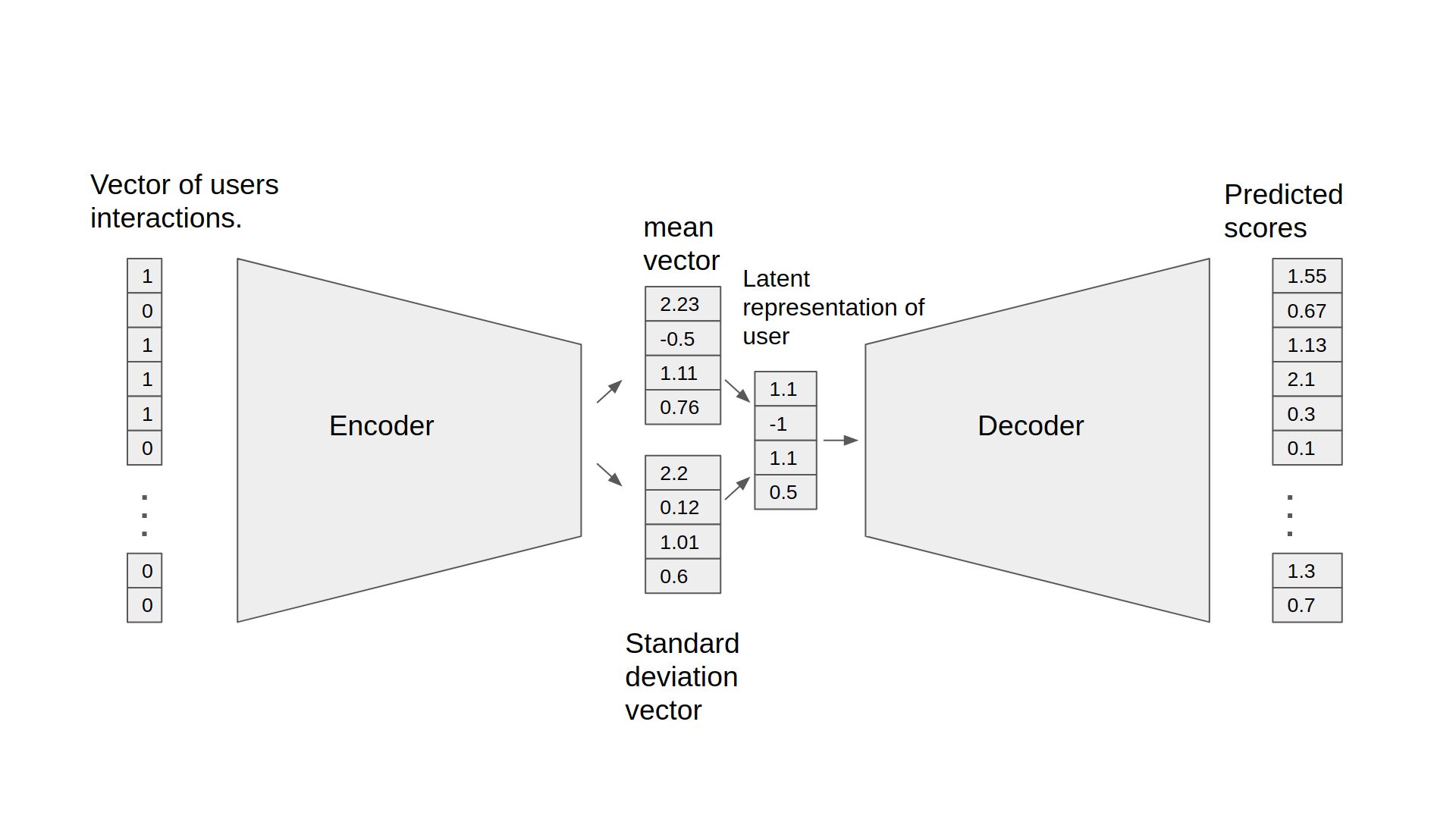
شبکههای خود رمزگذار چیست؟
به دلیل این که در این مدلها برای هر کاربر، علاوه بر آیتمها، یک بردار ویژگی نیز محاسبه میشود، پس می توان با محاسبه ضرب داخلی بردار محاسبه شده برای هر کاربر در تمامی آیتمها، میزان مشابهت(علاقه) آن کاربر با تمامی آیتمها را بدست آورد. یکی از بزرگترین محدودیتهای این مدل عدم توانایی آن در محاسبه بردار ویژگی برای کاربران خارج از دادههای آموزشی است. بنابراین برای کاربران جدید که در دادههای آموزشی قبلی حضور نداشتهاند نمی توان از این مدل استفاده نمود. برای رفع این محدودیت میتوان از روشهای مختلفی مانند روشهای مبتنی برای شبکههای خود رمزگذار(autoencoder) استفاده نمود.
هدف این نوع از شبکهها انتقال دادهها به یک فضای برداری با ابعاد کمتر است به گونهای که بتوان با استفاده از این فضای برداری، دادههای اصلی را بازسازی نمود. این شبکه ها از دو بخش اصلی تشکیل شدهاند:
بخش اول: رمزگذار(encoder) که وظیفه کاهش ابعاد دادههای ورودی را بر عهده دارد
بخش دوم: رمزگشا(decoder) که دادههای رمزگذاریشده را به حالت اولیه بر میگردانند.
به دلیل این که در این مدل از شبکههای عصبی، کاهش ابعاد داریم، شبکه باید توانایی نشان دادن دادهها در فضایی با ابعاد کمتر را فراگیرد. از این شبکهها میتوان در سیستمهای پیشنهاددهنده شخصی استفاده کرد. برای این منظور میتوان مجموعه دادهای متشکل از لیست فیلمهای مشاهدهشده توسط کاربران را جمع آوری کرد. بنابراین ورودی و خروجی این نوع شبکه میتواند لیست فیلمهای مشاهده شده توسط کاربر باشد.
نکته مهم در استفاده از این شبکهها برای سیستم پیشنهاد دهنده، استفاده از نوعی لایه مانند dropout پس از لایه ورودی است.
این لایه تعدادی از دادههای ورودی به شبکه را به صورت تصادفی حذف میکند. چون هدف شبکه بازسازی دادههای ورودی در لایه خروجی است باید در طول فرایند آموزش توانایی تخمین دادههای حذف شده را فرابگیرد. بنابراین پس از آموزش شبکه میتوان لیستی از فیلمهای مشاهدهشده توسط یک کاربر را به عنوان ورودی و لیست تخمین زده شده توسط شبکه را به عنوان خروجی( لیست پیشنهادی برای کاربر) در نظر گرفت. میتوان گفت، از مزیتهای اصلی این روش، امکان استفاده از آن برای کاربران جدید و قابلیت مقیاسپذیری بیشتر نسبت به مدل قبلی است.
ما در این سیستم از (Variational Autoencoder(VAE که نوع خاصی از شبکه خود رمزگذار است، استفاده میکنیم. دلایل استفاده از این مدل و اطلاعات تکمیلی را میتوانید در مقالهای که در منابع آورده شده مطالعه کنید.
نحوه ساخت ردیفها و صفحات
برای ساخت ردیفها و صفحات، دو موضوع پیش رو داشتیم:
- ساختن صفحات شخصی سازی شده
- ساختن صفحه کلی یا general
ساخت صفحات شخصی سازی شده
صفحات شخصیسازی شده برای کاربران فعال ساخته میشوند. برای ساخت ردیفها، مدل ما امتیازی به هر کاربر برای همه فیلم تولید می کند. این امتیازها برای شخصیسازی ردیفها و صفحات الزامی است. ما با استفاده از ویژگیها و اطلاعات فیلمها ردیفهایی را به طور کلی میسازیم. این ردیفها با استفاده از این امتیازها رتبه بندی و اولویتبندی میشوند و ردیفهایی که امتیاز بالاتری کسب کنند در جایگاه بالاتری در صفحه قرار میگیرند. همچنین در خود هر ردیف فیلمهایی که امتیاز بالاتری داشته باشند از سمت راست به ترتیب قرار میگیرند و از سویی دیگر برای ساخت و چیدمان بعضی ردیفهایی مانند «بر اساس فیلمی که شما دیده اید» یا «ادامه تماشا»، از پروفایل ساختهشده برای کاربران استفاده میکنیم.
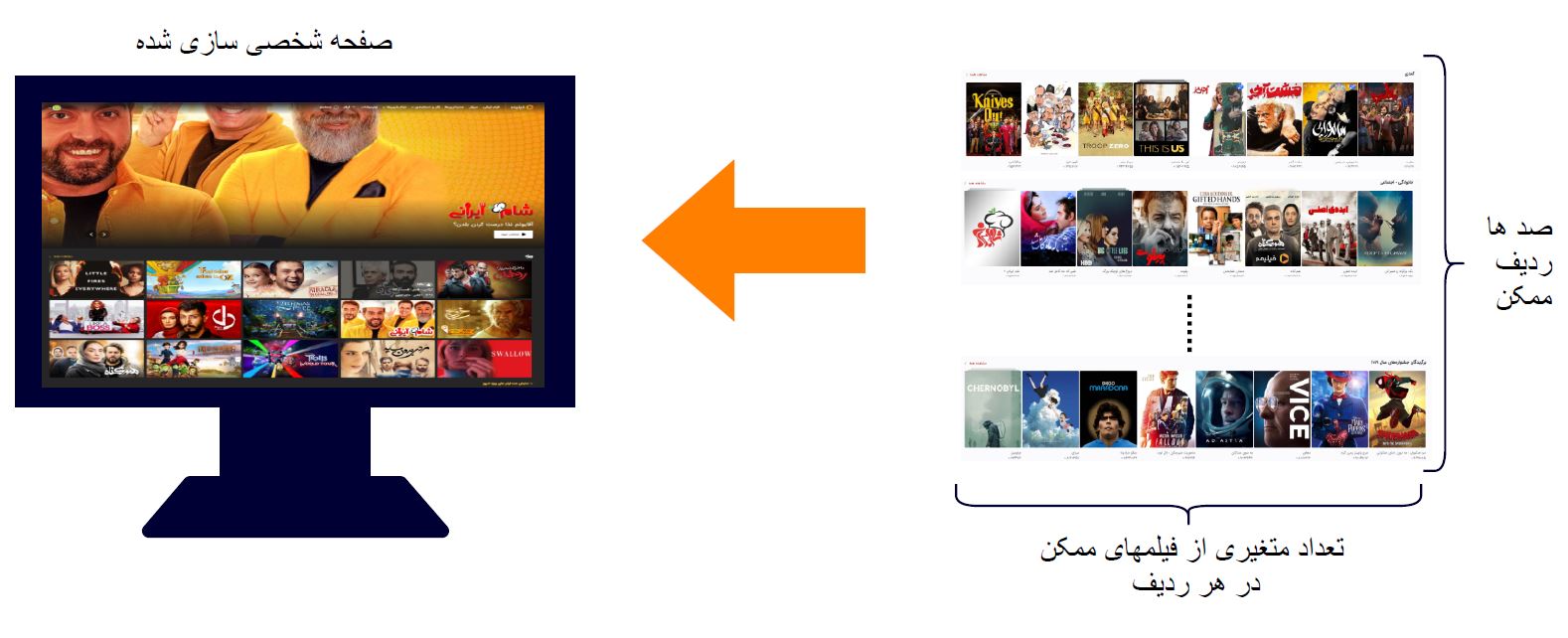
ساختن صفحه کلی یا general
صفحه کلی برای کاربرانی مورد استفاده قرار میگیرد که یا کاربر فعال نیستند یا کاربران جدید هستند. برای ساخت صفحه کلی ما از روشهای مختلفی استفاده کردیم:
- یکی از روشها استفاده از لایکها و امتیاز کاربران به فیلمها است. بدین صورت که فیلمهای محبوب، با استفاده از فرمولی که IMDB برای فیلمهای برتر استفاده میکند، در اولویت قرار میگیرند و امتیاز بالاتری کسب میکنند و در نتیجه ردیفها بر اساس علایق عمومی ساخته میشوند.
- روش دیگر استفاده از امتیازهای ساخته شده برای همه کاربران، در مدلهای Autoencoder یا LightFM بود، با استفاده از فرمول مطرح شده سلیقه کلی را محاسبه کردیم و ردیفها را بر اساس آن تشکیل دادیم. با توجه به نتایج ارزیابیها، صفحه کلی که با استفاده از امتیازهای مدل Autoencoder ساخته شد، بهترین بازخورد را داشت و مورد استفاده قرار گرفت.
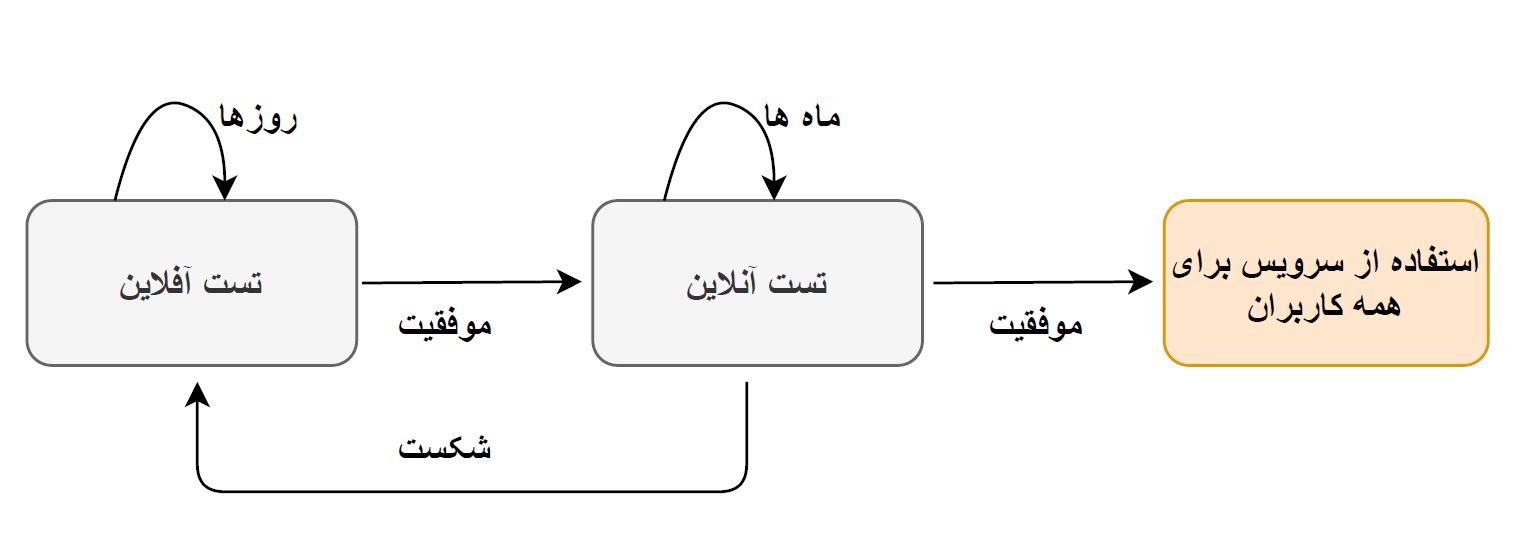
چطور ارزیابی میکنیم؟
برای ارزیابی سیستم پیشنهاددهنده شخصیسازی شده فیلیمو، ما ابتدا مدل برتر که بر اساس nDCG، که در مقاله قبل توضیح دادیم استفاده میکنیم، سپس صفحات ساختهشده برای کاربران را به صورت A/B تست ارزیابی میکنیم. در این ارزیابی ما از کاربران دو گروه تقریبا یکسان از نظر میزان تماشای فیلیمو انتخاب کردیم، و پس از چند روز تفاوت میزان تماشای کاربران را ارزیابی کردیم. ما برای این ارزیابی از ابزار google analytics استفاده کردیم.
نکته بسیار مهم!!!
ما برای ساخت این سیستم از تاریخچه تماشای کاربران استفاده میکنیم تا سلیقه کاربران را به دست آوریم. اما از اطلاعات شخصی کاربران استفاده نمیکنیم، در واقع همه اطلاعات به صورت کد شده در سیستم قرار دارند و این اطمینان را به کاربران میدهیم که از این اطلاعات صرفا برای افزایش کیفیت پیشنهادات استفاده میشود.
معماری کلی سیستمهای پیشنهاد دهنده
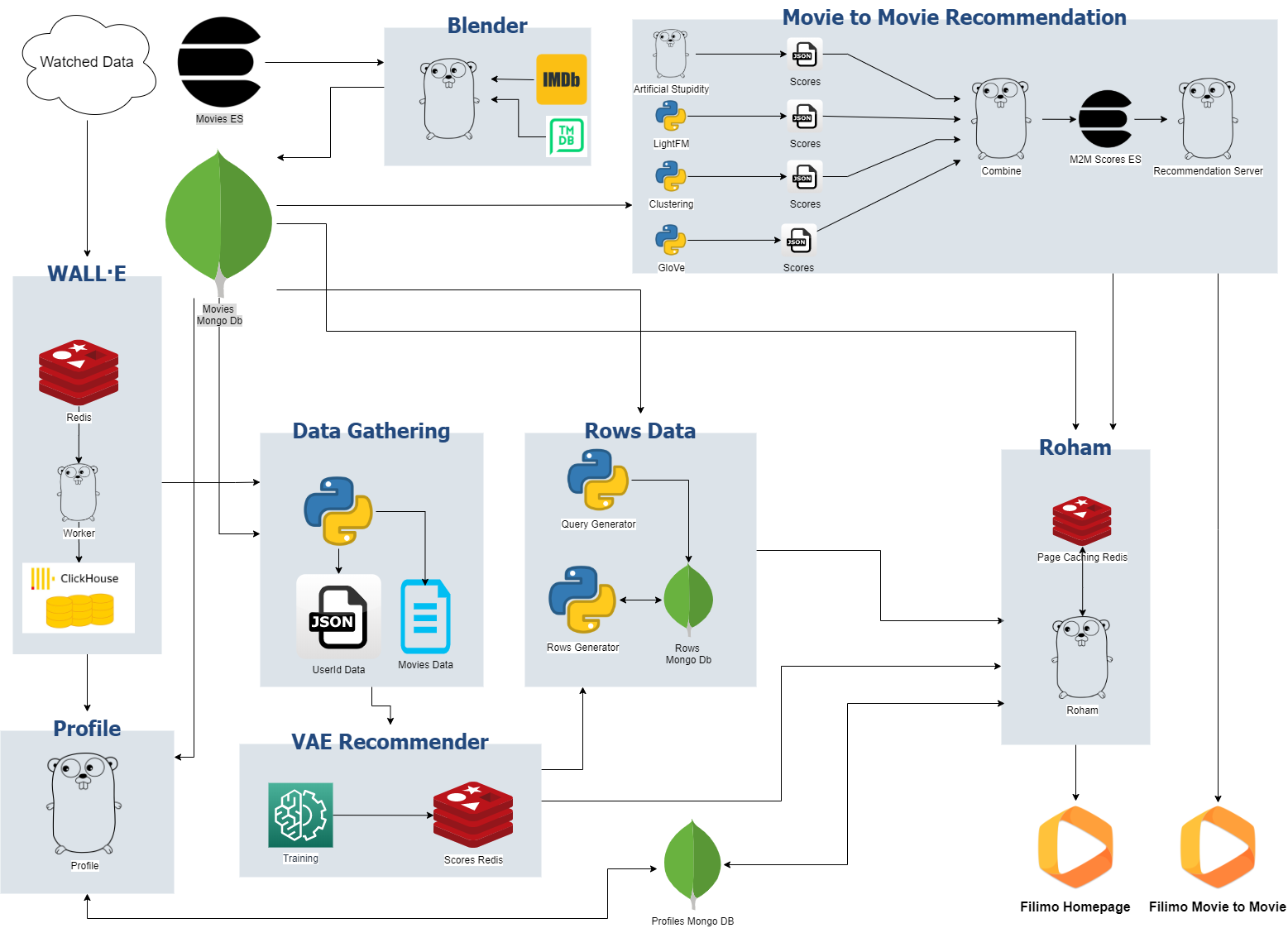
اجزای سیستم شامل این موارد هستند:
- سرویس پیشنهاددهنده «فیلم به فیلم»
- سرویس Wall-E
- سرویس پروفایل
- سرویس جمع آوری کننده داده
- سرویس توصیه کننده (Variational Autoencoder(VAE
- سرویس سازنده ردیفهای فیلیمو
- سرویس رهام
- سرویس Blender
سرویس پیشنهاد دهنده فیلم به فیلم:این سرویس در مقاله قبلی توضیح داده شد و از خروجی آن در بعضی ردیفها مانند «بر اساس فیلمی که دیدهاید» استفاده میشود.
سرویس Wall-E: این سرویس مسئول جمع آوری اطلاعات تماشای فیلم توسط کاربران و تجمیع (aggregation) و نگهداری آن است.
سرویس پروفایل: سرویس پروفایل وظیفه تولید شخصیت (persona) برای کاربران را دارد، روزانه برای کاربرانی که فیلم دیدهاند، لیست فیلمهای دیدهشده (watched)، پسندیدهشده(liked)، پسندیدهنشده(disliked) و نشانشده (bookmarked) را تشکیل میدهد، سپس از روی آن اطلاعات زیر را برای هر کاربر تولید میکند:
- توزیع رده سنی
- توزیع دستهبندی اول و دوم فیلم
- توزیع عوامل فیلم
- توزیع زمان (ساعت، روز) تماشای فیلم
- توزیع زمان(دهه) تولید و انتشار فیلم
- توزیع کشور(های) سازنده فیلم
- توزیع فیلم ها و سریالها
- توزیع تگها
- میانگین، حداقل و حداکثر امتیاز کاربران به فیلمها
- میانگین، حداقل و حداکثر طول فیلمها
- میانگین، حداقل و حداکثر تعداد دیدگاههای فیلم
- میانگین، حداقل و حداکثر تعداد بازیگران فیلم
همچنین این سرویس وظیفه دارد که لیستی از فیلمهای نیمه کاره دیدهشده و فیلمهایی که پتانسیل نشان داده شدن در ردیف پیشنهاد «بر اساس فیلمهای پسندیده شده» را دارند، تولید کند.
سرویس توصیه کننده (Variational Autoencoder(VAE: این سرویس در واقع همان مدل خود رمزگذاریشده است که در بالا به طور کلی و مختصر توضیح دادیم. خروجی این مدل، ماتریسی است که به ازای هر کاربر به همه فیلمها امتیازی داده میشود.
سرویس سازنده ردیفهای فیلیمو: این سرویس با استفاده از دادههای موجود در Redis، که توسط سرویس VAE تهیه شدهاست، ردیفهای فیلیمو را به صورت آفلاین، بهروزرسانی و برای نمایش به عنوان فیلیمو عمومی مورد استفاده قرار میدهد. فیلیمو نسخه عمومی از این ردیفها و امتیازها استفاده میکند.
سرویس رهام (row هام): این سرویس وظیفه سرو کردن نهایی ردیف فیلمهای صفحه اصلی و صفحات داخلی فیلیمو به صورت شخصیسازی شده را بر عهده دارد. این سرویس همچنین شامل زیرساخت A/B Test مجموعه نیز هست که هر کاربر را بر اساس شرطهای مشخص شده دستهبندی میکند و امکان A/B تست کردن مدلهای تولید شده را میدهد. به طور مثال، بر این اساس که آیا میتوان برای کاربر صفحه شخصیسازی شده تولید کرد یا نه (کاربر در مدت مشخص، تعداد کافی فیلم دیده باشد)، کاربرها به دو دسته بزرگ Personal و General تقسیمبندی میشوند و با ساخت دو گروه متشکل از نسبت مساوی از هر دو گروه A/B تست می شوند. سرویس رهام به صورتی بهینه پیادهسازی شده که بتواند در تعداد درخواست بالا نیز همچنان در محدوده چند میلی ثانیه به کاربران بدون سلیقه، ردیفها را به صورت General و برای کاربران دارای سلیقه، ردیفها را به صورت شخصی سازی شده سرو کند.
در حالت کلی ردیفها شامل چند دسته میشوند که فیلمها در هر ردیف بر اساس امتیازی که علاقه کاربر (در صورت داشتن سلیقه وگرنه میانگینی از علاقه همه کاربران دارای سلیقه) به فیلم نشان میدهد، مرتب میشوند. سپس براساس مجموع امتیاز چند فیلم اول هر ردیف، امتیاز ردیف بدست میآید، ردیفها با آن امتیاز در محدودهای که از قبل مشخصشده مرتب میشوند.
به طور مثال، ردیف «دوباره ببینید» میتواند در بازه ردیفهای ۱۰ تا ۳۰ قرار بگیرد و تا چند دقیقه cache شود، تا در درخواستهای بعد کاربر بتوان بلافاصله آنها را سرو کرد، این ردیفها به دستههای زیر تقسیم میشوند:
- ردیفهای عادی از پیش تشکیل شدهاند.
- ردیفهای ثابت که یا اطلاعات ثابتی دارند یا توسط بخشهای دیگر فیلیمو پر میشوند.
- ردیفهای پویا (dynamic) که در لحظه درخواست تولید میشوند. به طور مثال، ردیف «به تماشا ادامه دهید» که در لحظه بر اساس profile کاربر تشکیل میشوند.
- ردیفهای پویا که توسط سرویسهای دیگر مقداردهی میشوند. به طور مثال، ردیف «بر اساس فیلم X که دیدهاید» که فیلم منتخب از profile کاربر استخراج میشود ولی برای تشکیل ردیف نیاز به درخواست اطلاعات از سرویس recommendation server است.
سرویس Blender: این سرویس وظیفه غنیسازی (enrichment) اطلاعات فیلمهای فیلیمو با هدف در دست داشتن دادههای متای(meta data) بیشتر برای مدلهای پیشنهاد فیلم را بر عهده دارد و به صورت مداوم اطلاعات سایتهای مرجع فیلم مانند IMDB و TMDB را به صورت بهروز دریافت میکند و در کنار اطلاعات فیلمهای فیلیمو قرار میدهد.
مسیر تیم هوشمندسازی در آینده
مهمترین بخشی که در نظر داریم در آینده به آن بپردازیم ساختن زیر ساخت مناسبتر برای دریافت دیتا و داشتن دیتای بیشتر از کاربران است. در ادامه مدلهای بسیاری از جمله مدلهای مبتنی بر گراف وجود دارند که قصد ارزیابی آنها را پیش رو داریم و در مدلهای موجود به مواردی چون تستهای متفاوت، بهتر شدن از لحاظ دقت، کارایی و سرعت پاسخدهی بپردازیم، در نهایت امیدواریم بتوانیم با ساختن یک سیستم پیشنهاددهنده مناسب، محصول با کیفیتتری به کاربران ارائه دهیم.
نکاتی در مورد پست اول
با توجه به نظرات و بازخوردهای مطرح شده در پست اول، دو نکته را لازم است بیان کنیم.
- در سیستم پیشنهاد دهنده «فیلم به فیلم»، مدلهایی مانند word2vec و GloVe اگرچه از اطلاعات تاریخچه تماشای کاربران، فقط برای به دست آوردن شباهت بین فیلمها استفاده میکنند، اما میتوانند در زیرمجموعه مدلهای پالایش گروهی (collaborative filtering) قرار گیرند. زیرا با توجه به تعریف جامعتر پالایش گروهی، هر مدلی که از دیتا کاربران استفاده کرده و از اطلاعات آن به طور ضمنی در مدلی به کار برد، آن مدل نیز میتواند در زیرمجموعه پالایش گروهی قرار گیرد.
- در مدلهای word2vec و GloVe ترتیب تماشای فیلم در طول زمان اهمیت دارد و نتایج آنها موقتی هستند. به عبارت دیگر، مدلهای ما این توانایی را دارند که در صورت تغییر سلیقه کاربران، فیلمهای پیشنهاد شده، با توجه به تاریخچه تماشای فیلمها در طول زمان، تغییر کنند.
کلام آخر
ما در این دو مقاله به صورت مختصر دو سیستم پیشنهاددهنده در فیلیمو را شرح دادیم. چالشها، روشها، نحوه کارکرد و ارزیابی هر دو سیستم پیشنهاد دهنده «فیلم به فیلم» و سیستم «صفحه شخصی سازی شده» را بیان کردیم. به طورکلی نتیجهای قابل مشاهده، این است که، این سیستمها در قسمتهایی برای بهبود همدیگر با هم در ارتباط هستند و در کل باعث افزایش استفاده کاربران از محصول شدهاند و کیفیت آن را افزایش دادهاند.
در آخر از همه اعضای تیم و کسانی که در نوشتن این دو پست به ما کمک کردند تشکر میکنم. در ضمن از دوستانی که نظر و بازخوردشان را اعلام کردند، مخصوصا آقای بهنام ثابتی، که ابهامات ذکر شده را مطرح کردند، ممنونیم. امیدواریم که این مطالب برای دوستان مفید واقع شده باشد.
منابع
- https://netflixtechblog.com/learning-a-personalized-homepage-aa8ec670359a
- https://towardsdatascience.com/recommendation-system-part-1-use-of-collaborative-filtering-and-hybrid-collaborative-content-in-6137ba64ad58
- https://medium.com/recombee-blog/evaluating-recommender-systems-choosing-the-best-one-for-your-business-c688ab781a35
- https://netflixtechblog.com/page-simulator-fa02069fb269
- https://towardsdatascience.com/intuitively-understanding-variational-autoencoders-1bfe67eb5daf
- https://github.com/mkfilipiuk/VAE-CF
مطلبی دیگر از این انتشارات
۴۰۴ هم صفحهای از سایت شماست!
مطلبی دیگر از این انتشارات
سیستم پیشنهاددهنده اولیه فیلیمو (Jump Start Recommendation System)
مطلبی دیگر از این انتشارات
معرفی سیستم های Caching و استفاده آنها در آپارات